

Preise steigen und Limits schrumpfen
Ich wechsle bei Claude je nach Projekt zwischen Pro, Max 5x und Max 20x. Heißt: Wenn ich gerade ein Vibe-Coding-Projekt habe, gehe ich auf 200 Dollar im Monat. Wenn nicht, reichen 20 Dollar. Dazu kommen ChatGPT Plus und Google Gemini. Und letzte Woche hat mir mein KI-Coding-Agent mitgeteilt, dass mein wöchentliches Limit erreicht sei. An einem Mittwoch. Um 13 Uhr.
Ich bin anscheinend zu gut darin, Geld für Künstliche Intelligenz auszugeben. Und zu neugierig, um bei einem Abo stehenzubleiben. Vermutlich ist das ein Muster an mir.
Und ich bin nicht der Einzige, dem das auffällt. Seit ein paar Wochen passiert etwas in der KI-Ökonomie, das nach einer Verschiebung riecht. Preise steigen. Limits schrumpfen. Features verschwinden aus Abo-Plänen. GitHub stoppt Anmeldungen. „The AI economy is about to change“ titeln KI-Blogs. Und auf LinkedIn posten Leute Abschiedsbriefe an ihre Lieblings-KI-Tools, als wäre gerade jemand gestorben.
Die Erzählung, die sich gerade festsetzt: KI-Firmen werden gierig. Die Subventionen enden. Die Party ist vorbei. Alles wird teurer und schlechter.
Das stimmt so nicht. Jedenfalls nicht so einfach. Die Wahrheit dahinter ist komplizierter. Und offen gesagt auch deutlich interessanter.
Ich will das hier aufdröseln. Nicht weil ich den Durchblick gepachtet habe. Sondern weil ich als jemand, der seit 2022 jeden Tag mit künstlicher Intelligenz arbeitet und dafür echtes Geld bezahlt, verstehen will, was mit meinem Geld passiert. Und warum es plötzlich weniger Rechenleistung dafür gibt.

Die sichtbaren Risse
Die Veränderungen kamen Schlag auf Schlag. Und sie kamen von überall gleichzeitig.
Anthropic hat vor ein paar Wochen einen sogenannten Painted-Door-Test durchgeführt. The Register hat das dokumentiert: Manche Nutzer sahen beim Öffnen der Pricing-Seite plötzlich, dass Claude Code nur noch ab dem 100-Dollar-Plan verfügbar war. Das 20-Dollar-Abo? Ohne Coding-Agent. Kein Opt-in, keine Vorwarnung. Ein Test, um zu sehen, wie viele Leute trotzdem bleiben, wie viele upgraden und wie die Zahlen sich verschieben.
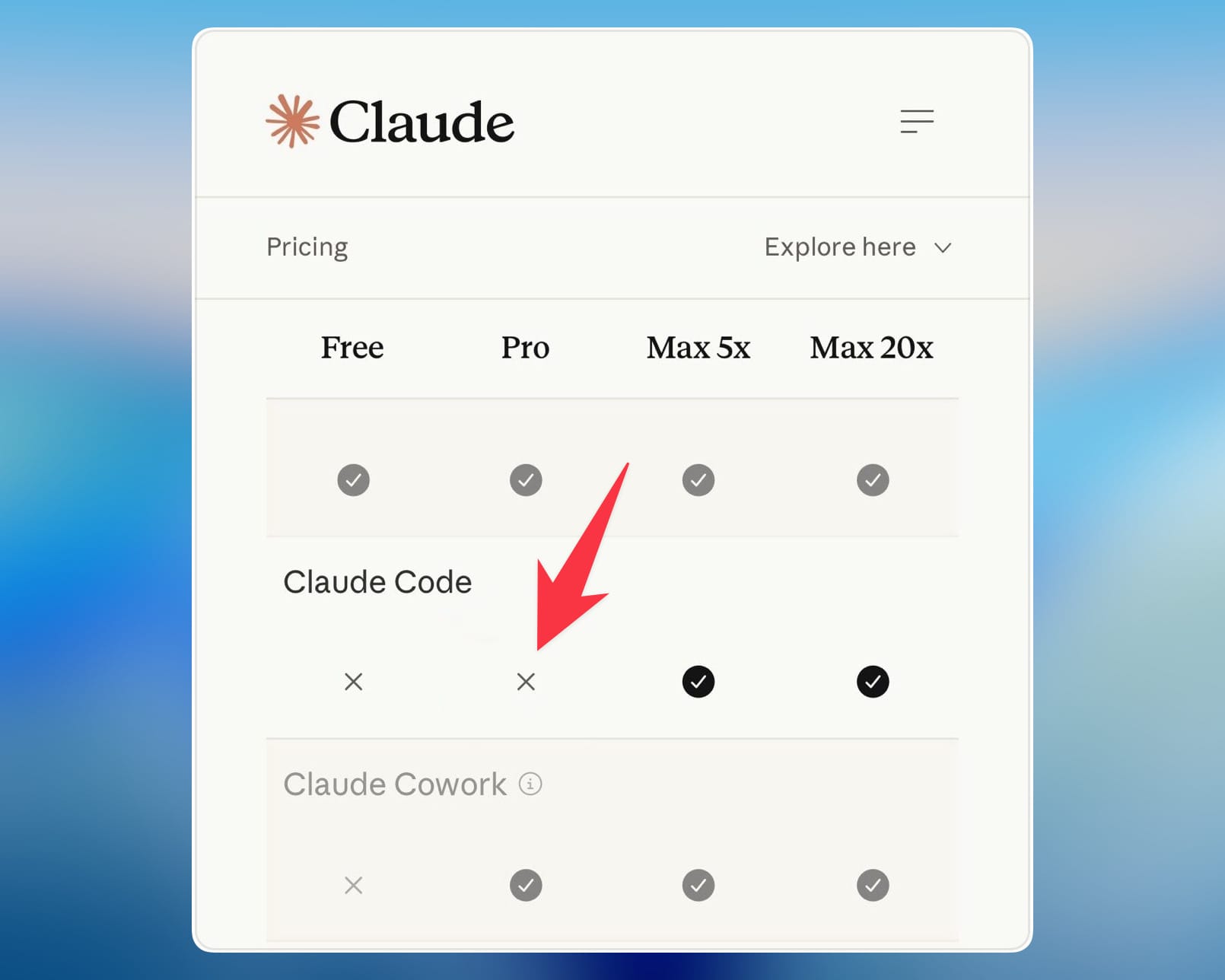
Das klingt nach Upselling. Genau so wurde es diskutiert. Aber wenn du tiefer schaust, siehst du was anderes.
Praktisch gleichzeitig hat Microsoft bei GitHub Copilot umgestellt. Bisher hast du eine bestimmte Anzahl Nachrichten pro Monat bekommen. 1.500 auf dem 40-Dollar-Plan. Jetzt läuft alles über Token-Budgets. Klingt nach einem kleinen technischen Detail. Ist es nicht.
Stell dir vor, der Supermarkt rechnet nicht nach dem Preis deiner Einkäufe ab, sondern danach, wie viele Dinge du im Wagen hast. Zwei Packungen Kaugummi zählen gleich viel wie ein 65-Zoll-Fernseher. So hat Copilot bisher funktioniert.
Eine Nachricht an GPT 5.4 über Copilot hat genauso gezählt wie eine Nachricht an GPT 5.5, obwohl 5.5 das 7,5-fache an Rechenleistung braucht. Eine einzige komplexe Anfrage kann stundenlang laufen und dabei hundert Dollar an Compute (Rechenleistung) verbrauchen. Für eine Nachricht. Von 1.500.
Das konnte auf Dauer nicht funktionieren.
Die wirtschaftliche Seite von KI
Und dann kam der Schlag, der für mich am aufschlussreichsten war: Microsoft hat die Anmeldungen für Copilot komplett pausiert. Nicht die Preise erhöht. Nicht Features gestrichen. Anmeldungen gestoppt. Und in der Begründung stand ein Satz, der alles sagt: „Long-running, parallelized sessions now regularly consume far more resources than the original plan structure was built to support.“
Das macht man nicht, wenn man mehr Geld verdienen will. Das macht man, wenn man nicht genug Kapazität hat.
Hier die Timeline der sichtbaren Veränderungen, die mich wachgerüttelt haben:
- Cursor war der Erste: Schon Mitte 2025 wechselten sie von Nachrichten-Limits auf nutzungsbasierte Abrechnung, weil manche User mit ihren 200 Nachrichten 10 Dollar an Compute verbrauchten und andere tausende
- Anthropic experimentierte mit Nutzungs-Limits: Erst großzügige Promotions, dann strengere Beschränkungen bei hoher Auslastung. Innerhalb weniger Wochen
- Anthropic testete die Entfernung von Claude Code aus dem 20-Dollar-Plan
- GitHub Copilot wechselte auf Token-Budgets und pausierte gleichzeitig Neuanmeldungen. Laut geleakten internen Dokumenten haben sich die wöchentlichen Kosten für den Betrieb von Copilot seit Jahresbeginn verdoppelt
- Google sperrte Nutzer, die zu aggressiv die kostenlosen Gemini-Kapazitäten ausgereizt hatten
Die oberflächliche Analyse: KI-Firmen werden gierig. Die Subventionen enden. Die Party ist vorbei.
Meine Analyse nach ein paar Wochen im Rabbit Hole: Falsch. Komplett falsch.
Das Problem heißt Compute
Ich habe mich in die Zahlen reingefressen. Tiefer, als ich eigentlich vorhatte. Und je mehr ich verstanden habe, desto klarer wurde mir: Hier geht es nicht darum, dass Anthropic oder Microsoft mehr Geld aus dir pressen wollen. Die interessieren sich kaum für deine 20 oder 200 Dollar im Monat.
Ich weiß. Das klingt strange. Du zahlst Geld, und die finden das unwichtig? Willkommen in der KI-Ökonomie.
Was sie interessiert: Enterprise-Kunden. Unternehmen, die über die API zahlen. Voller Preis, kein Rabatt, kein Subventionsnetz. Uber hat gerade zugegeben, ihr gesamtes KI-Jahresbudget in vier Monaten verbraucht zu haben. Ubers CTO Praveen Neppalli Naga sagte gegenüber „The Information“, er müsse „zurück ans Reißbrett“, weil das Budget, mit dem er gerechnet hatte, schon weg sei. Und die zahlen nicht die Abo-Preise. Die zahlen API‑Raten. 84 Prozent der Uber-Entwickler nutzen mittlerweile KI-Agenten monatlich, mit Kosten von 500 bis 2.000 Dollar pro Entwickler.

Die Rechnung, die mich wachgerüttelt hat
Wenn du für 200 Dollar im Monat Claude Code nutzt, bekommst du laut einer Forbes-Analyse Rechenleistung im Wert von bis zu 5.000 Dollar. Gemessen an den API-Preisen (!). DeSight Studio hat die Subventionsquote durchgerechnet: Bei extremen Power-Usern liegt das Verhältnis bei 25:1. 200 Dollar rein, bis zu 5.000 Dollar raus. Manche verbrauchen laut deren Analyse sogar API-Äquivalente von über 2.600 Dollar pro Monat, was Anthropic rund 87.600 Dollar Verlust pro Jahr und Nutzer beschert.
API-Preise enthalten massive Margen
Martin Alderson hat genau diese Zahl auseinandergenommen und einen wichtigen Punkt gemacht: Die 5.000 Dollar sind API-Preise, keine Infrastrukturkosten. API-Preise enthalten massive Margen. Wenn du die tatsächlichen Rechenkosten schätzt, anhand vergleichbarer Open-Weight-Modelle auf OpenRouter, landest du eher bei 500 Dollar pro Heavy-User. Ein Verlust von 300 Dollar pro Monat statt 4.800.
Trotzdem: Selbst 300 Dollar Verlust pro Nutzer, multipliziert mit hunderttausenden Power-Usern, ist kein nachhaltiges Geschäftsmodell. Die 5.000-Dollar-Zahl beschreibt eher den entgangenen API-Umsatz, den Anthropic mit einem Enterprise-Kunden hätte machen können. Und genau das ist der Punkt: Jeder Token, den ein 200-Dollar-Abo verbraucht, ist ein Token, den ein Fortune-500-Unternehmen nicht kaufen kann.
Dein Abo ist kein Produkt. Es ist eine Wette darauf, dass du irgendwann Enterprise-Kunde wirst.
Und wer redet in diesem Zusammenhang über Google? Fast niemand. Dabei sind die vermutlich der aggressivste Subventionierer von allen. Jede Google-Suche mit AI Overview ist kostenlose Rechenleistung. Für jeden. Inkognito-Modus, ausgeloggter Browser, egal. Volle KI-Antworten, kostenlos.
Google war so aggressiv, dass sie als Erste zurückrudern mussten. Nutzer, die Plugins gebaut haben, um ihre Gemini-Nutzung zu tracken oder mit externen Code-Editoren zu verbinden, wurden gesperrt. Noch vor Microsoft. Noch vor Anthropic. Dass kaum jemand darüber spricht, liegt an zwei Dingen:
- Google war zu früh zu großzügig und musste deshalb schneller einschränken.
- Googles Modelle waren lange einfach nicht gut genug, um Schlagzeilen zu machen.
Der Engpass ist universal. Er betrifft jedes KI-Unternehmen auf dem Planeten. Und er hat einen simplen Grund: Es gibt nicht genug Nvidia-Chips. Die Nachfrage nach Rechenleistung wächst schneller als die Produktion. Selbst Nvidia, die die Dinger herstellen, sind limitiert durch ihre Zulieferer.
Hier die Zusammenhänge, die mir beim Verstehen geholfen haben:
- Google sperrte Nutzer nicht aus Profitgier, sondern aus Kapazitätsnot
- Microsoft hat Copilot-Anmeldungen nicht pausiert, um Geld zu scheffeln. Sie haben pausiert, weil sie die GPUs für Enterprise-Kunden brauchen, die echtes Geld bezahlen
- Anthropic will Claude Code nicht aus dem 20-Dollar-Plan entfernen, um dich auf 100 Dollar hochzudrücken. Sondern um Compute freizuschaufeln für die Kunden, die das zehnfache zahlen
- OpenAI hat schon 2023 ChatGPT-Plus-Anmeldungen pausiert. Sam Altman schrieb damals auf X: Die Nachfrage hat unsere Kapazität überstiegen. Danach haben sie massiv eingekauft und haben das Problem heute nicht mehr. Nicht weil sie mehr Geld haben. Weil sie mehr GPUs haben.
we are pausing new ChatGPT Plus sign-ups for a bit :(
— Sam Altman (@sama) November 15, 2023
the surge in usage post devday has exceeded our capacity and we want to make sure everyone has a great experience.
you can still sign-up to be notified within the app when subs reopen.
Das klingt alles dramatisch. Und ein Stück weit ist es das auch. Aber es gibt eine zweite Seite dieser Geschichte. Und die stimmt mich offen gesagt optimistisch.
Warum die KI-Kosten trotzdem sinken
Und hier fängt der Teil an, der mich als jemand, der täglich mit künstliche Intelligenz arbeitet und dafür bezahlt wird, am meisten fasziniert.
Ja, die Frontier-Modelle werden teurer. GPT 5.5 kostet pro Token doppelt so viel wie 5.4. Opus 4.5 hat vermutlich knapp eine Milliarde Dollar an Pre-Training gekostet. Die absoluten Zahlen steigen.
Aber die Kosten pro erledigte Aufgabe? Die fallen. Und zwar schnell.
Opus 4.5 war so ein neuer Pre-Training-Lauf. Teuer. Aber auch der Grund, warum es dreimal günstiger wurde als ältere Opus-Modelle, weil Anthropic es vermutlich kleiner und gleichzeitig schlauer gebaut hat als die Vorgänger.
Opus 4.6 und Opus 4.7? Post-Training. Feintuning, Reinforcement Learning, Verhaltensoptimierung. Deutlich günstiger.
Stell dir Pre-Training vor wie den Bau eines neuen Gebäudes. Post-Training ist die Renovierung einzelner Zimmer. Beides verändert das Haus, aber die Kosten sind grundverschieden.
Dario Amodei, der Chef von Anthropic, hat das mal in einem Interview so formuliert, und ich paraphrasiere: Wenn du jedes KI-Modell als eigene Firma betrachtest, die du ins Leben gerufen hast, ist es profitabel. Du investierst 100 Millionen ins Training und machst 200 Millionen Umsatz damit. Das Problem ist, dass du gleichzeitig eine Milliarde in das nächste KI-Modell steckst. Die Firma verliert Geld. Aber das einzelne KI-Modell verdient welches.
Das hilft mir beim Verständnis, weil es erklärt, warum die KI-Unternehmen weitermachen, obwohl die Zahlen auf den ersten Blick verrückt aussehen.
Jedes KI-Modell verdient Geld. Das Problem ist das nächste.

Jedes Modell amortisiert sich. Nur kommt sofort das nächste, das noch teurer ist. Kennt jeder aus der Tech-Branche: Dein aktuelles Produkt verdient Geld. Aber du investierst alles in das Nächste, weil du weißt, dass der Markt nicht wartet. Gewinn und Risiko laufen parallel. Genau das passiert gerade bei Anthropic, OpenAI und Google. Es ist wie ein Restaurant, das profitabel arbeitet, aber ständig in den Umbau einer noch größeren Küche investiert.
Die Zahlen haben mich wirklich überrascht. Ich habe mir die Benchmark-Daten angeschaut, die der Artificial Analysis Intelligence Index veröffentlicht hat:
GPT 5.5 auf der höchsten Stufe hat den Index-Run mit einem Score von 60 abgeschlossen. GPT 5.4 lag bei 57. Klingt nach wenig Unterschied. Aber die Kosten erzählen die eigentliche Geschichte: OpenAI bestätigt, dass 5.5 pro Token doppelt so viel kostet wie 5.4 (5 Dollar statt 2,50 pro Million Input-Tokens). Trotzdem lag der Gesamtpreis pro Index-Run nur etwa 20 Prozent höher. Warum? Weil GPT 5.5 rund 40 Prozent weniger Tokens braucht, um zum selben Ergebnis zu kommen.
Aber hier wird es spannend: GPT 5.5 Medium. Liefert laut Artificial Analysis ungefähr die gleiche Intelligenz wie Claude Opus 4.7 auf der höchsten Stufe. Kosten: rund 1.200 Dollar pro Index-Run. Opus 4.7 auf Maximum: rund 4.800 Dollar. Ein Viertel des Preises für vergleichbare Leistung.
Und GPT 5.5 Low, das für den KI-Chatbot bei wenighair mittlerweile mein Standard ist: kostet einen Bruchteil davon. Bei einem Intelligenz-Level, das laut Artificial Analysis immer noch mit älteren Frontier-Modellen mithalten kann.
Das Muster ist eindeutig. Bei gleichem Intelligenzniveau fallen die Preise rapide.
Das ist, was die „KI wird zu teuer“-Erzählung auslässt. Die KI-Frontier steigt, klar. Aber die Kosten für eine bestimmte Aufgabe fallen rapide. Was heute das beste KI-Modell kann, kann in sechs Monaten ein Modell, das ein Bruchteil davon kostet. Die Modelle werden schlauer. Und gleichzeitig effizienter. Beides passiert parallel.
Das finde ich beruhigend. Und gleichzeitig frustrierend.
Beruhigend, weil die Richtung stimmt. Die Kosten pro erledigter Aufgabe sinken. Jeden Monat. Das ist keine Prognose, das sieht man in den Daten.
Frustrierend, weil der Preis, den wir als Endnutzer zahlen, kaum etwas mit den tatsächlichen Kosten zu tun hat. Wir zahlen nicht für Rechenleistung. Wir zahlen für den Zugang zu einer knappen Ressource. Wenn Microsoft das 7,5-fache für GPT 5.5 berechnet, obwohl es pro Aufgabe billiger ist als 5.4, dann nicht weil es teurer ist. Sondern weil sie die GPUs für Enterprise-Kunden reservieren wollen und dich als 40-Dollar-Nutzer aus dem Weg haben möchten.
Ich finde das nachvollziehbar. Und gleichzeitig absurd. Zwei Dinge, die gleichzeitig wahr sein können.
Die Knappheit wird sich lösen. Nicht morgen. Aber die GPU-Produktion skaliert hoch, neue Architekturen kommen, und die Effizienzgewinne bei den Modellen kompensieren bereits jetzt einen großen Teil des Engpasses. OpenAI hat letztes Jahr massiv Kapazität aufgebaut und hat die Probleme von 2023 heute nicht mehr. Nicht weil sie reicher geworden sind. Weil sie mehr Hardware haben.
Vermutlich wird es kurzfristig noch enger, bevor es besser wird. Aber die Richtung stimmt. Und wer die wirtschaftliche Seite von künstlicher Intelligenz versteht, trifft bessere Entscheidungen als jemand, der nur die Tools nutzt und sich wundert, warum sie plötzlich langsamer, dümmer oder teurer werden.

Ich stoße immer noch regelmäßig an meine Limits. Werde ich vermutlich noch eine Weile tun. Aber ich verstehe jetzt, warum. Und das macht den Unterschied zwischen Frust und: okay, da steckt ein System dahinter, das sich gerade selbst sortiert.
Es werden gerade die Weichen gestellt, wie wir in den nächsten Jahren für künstliche Intelligenz bezahlen. Als Einzelperson, als Unternehmen, als Gesellschaft. Die Frage, ob KI zu teuer wird, hat keine einfache Antwort. Auf die Frontier, die Spitze der KI geschaut: Ja, die wird teurer. Auf das, was du für einen bestimmten Job erledigt bekommst: Das wird billiger. Jeden Monat ein bisschen mehr.
Und das finde ich, trotz aller Limits und Budgetschocks, ziemlich nice.
✺ Studio Christos